 ☰
🔍
☰
🔍
 ☰
🔍
☰
🔍
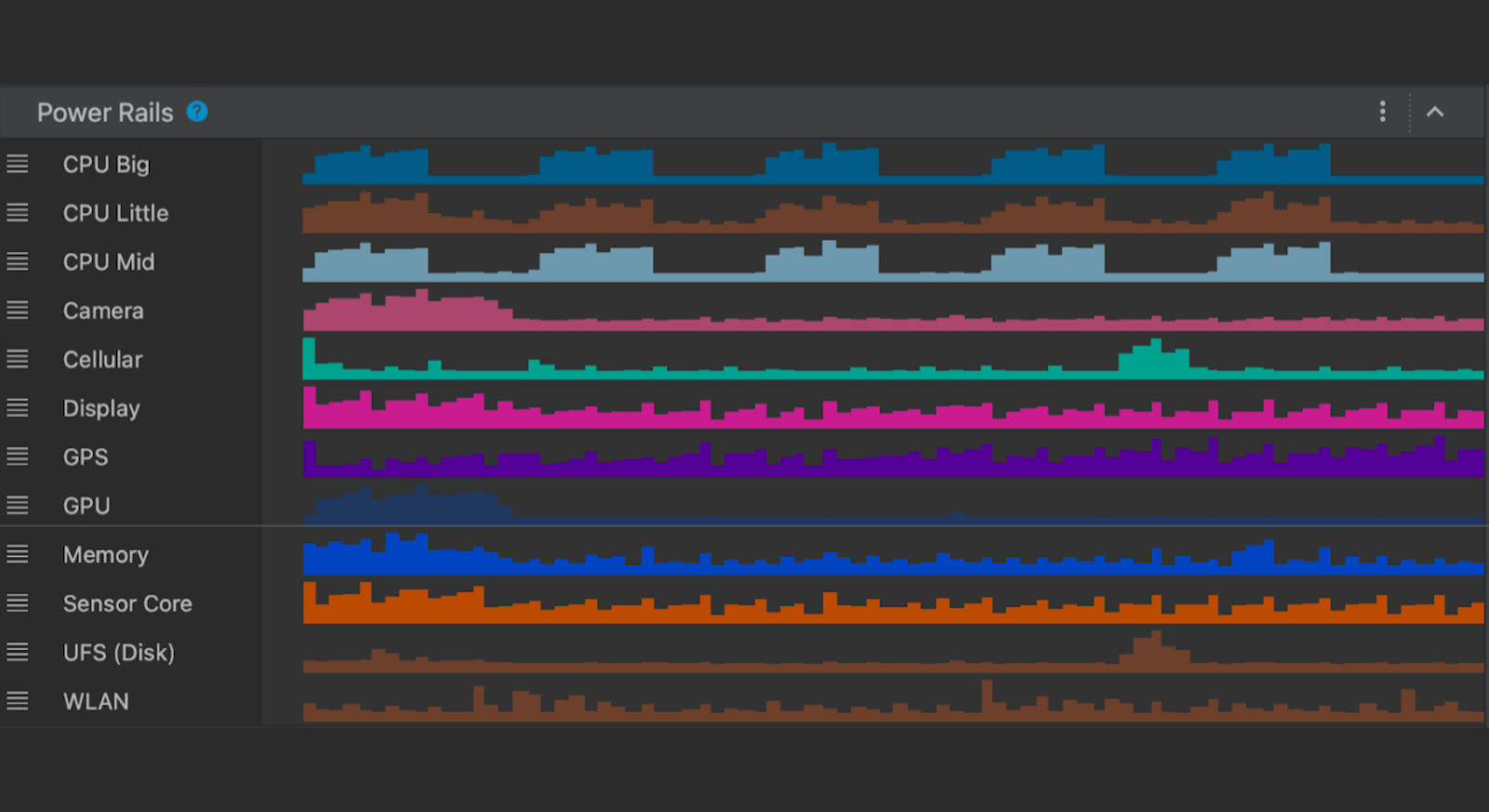
17 April 2024
Posted by Mayank Jain - Product Manager, and Yasser Dbeis - Software Engineer; Android Studio Android developers have been telling us...

09 April 2024
Posted by Nick Butcher – Product Manager for Jetpack Compose, and Florina Muntenescu – Developer Relations Engineer As one of the w...

08 April 2024
Posted by Sandhya Mohan – Product Manager, Android Studio As part of the next chapter of our Gemini era, we announced we were bringin...
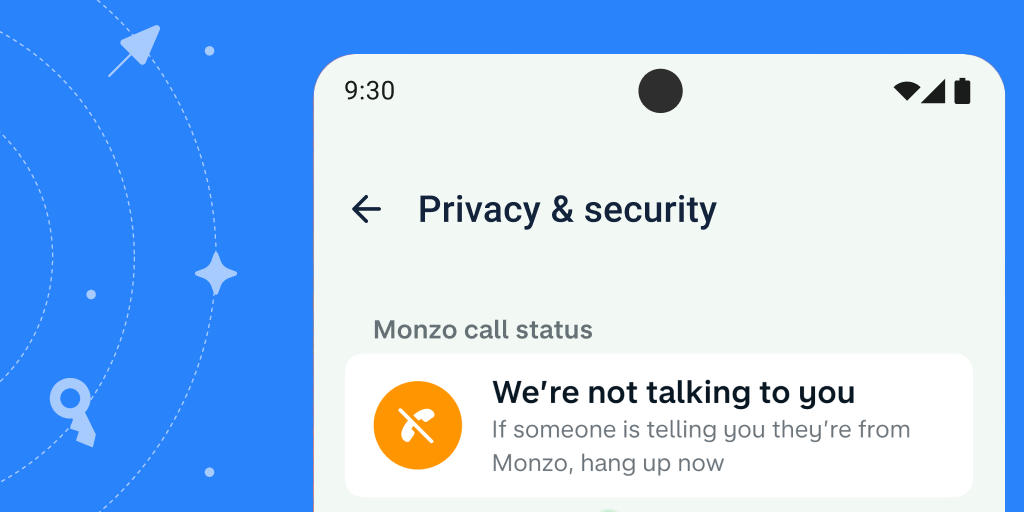
29 March 2024
Posted by Todd Burner – Developer Relations Engineer Cybercriminals continue to invest in advanced financial fraud scams, costing co...

25 March 2024
Posted by Leticia Lago – Developer Marketing In celebration of Women’s History month, we’re celebrating the founders behind groundb...

21 March 2024
Posted by Dave Burke , VP of Engineering Today marks the second chapter of the Android 15 story with the release of Android 15 Devel...
Android Developers


 Google Play
Google Play

